
GPT vs Claude: qual è il modello migliore per il mondo finance?
di Ivan Masnari e Damiano Gasparotto, rispettivamente Developer e Data Scientist in Excellence Innovation
I modelli di intelligenza artificiale sono entrati per restare nella nostra operatività quotidiana. Non importa l’ambito di applicazione, la loro capacità di comprendere il linguaggio umano, di ragionare e scrivere li ha resi uno strumento insostituibile per i professionisti di ogni disciplina. L’integrazione di questa tecnologia nel tessuto produttivo sarà un processo lungo e che dovrà seguire la rapida evoluzione che stanno avendo gli LLM.
Il 2023 ha visto, quasi quotidianamente, il rilascio di LLM sempre più potenti: Claude 2 (Anthropic), GPT-4 (OpenAI) oltre ad un numero imprecisato di modelli open-source. Questo inizio d’anno ha portato con sé una nuova serie di rilasci di LLM dalle performance impressionanti come la nuova famiglia LLama 3 di Meta o i modelli Mistral della francese Mistral AI.
Quello che ha catturato la nostra attenzione qui ad Excellence Innovation e che sarà il protagonista di questo articolo è il nuovo prodotto di Anthropic, la famiglia di modelli Claude 3 rilasciati lo scorso marzo. Claude 3 viene in tre versioni: Haiku (la più piccola e la più veloce), Sonnet (per compiti più complessi) e Opus (la più grande e più potente). Da subito Claude 3 Opus è balzato alla ribalta delle classifiche superando sui principali benchmark il leader indiscusso del mercato fino ad allora: GPT-4 di OpenAI (fonte: https://medium.com/@AhmedF/anthropics-claude-3-beats-gpt-4-across-main-metrics-feb72963564a).
Bisogna, tuttavia, ricordare che questi modelli rilasciati da compagnie come OpenAI, Anthropic, Meta etc. sono modelli generalisti, ovvero modelli creati per adattarsi ad un ampio spettro di scopi e non ottimizzati per nessuno di questi. Le metriche utilizzate per testare questi modelli e per stilare le classifiche che si trovano su Internet sono lo stesso metriche generaliste che non misurano le capacità di questi modelli in un ambito specifico di applicazione, ma sulle loro capacità di ragionamento logico-matematico o la loro abilità nella comprensione del linguaggio umano.
Come fare, quindi, a testare quale modello è effettivamente il più adatto al vostro mercato? Bisogna partire da una collezione di domande e risposte che siano rappresentative del tipo di informazione che il modello pensate debba possedere. Questo può essere fatto manualmente, creando da zero una collezione di questo genere, oppure ci si può appoggiare a piattaforme che raccolgono migliaia di benchmark caricati dagli utenti per gli scopi più disparati. Una volta trovato e/o creato il proprio benchmark, si chiede al modello di rispondere alle domande e si confrontano le sue risposte con quelle di controllo presenti nel benchmark.
Nel nostro studio presso Excellence Innovation, abbiamo voluto verificare quanto i modelli abbiano già una competenza intrinseca su specifici andamenti di mercato, in particolare nel settore finanziario americano, in un periodo temporale specifico (2019 in poi), senza ricorrere a risorse di conoscenza esterne. Per fare questo abbiamo attinto ad un dataset creato dall’università di Stanford di 150 domande/risposte. Il dataset è stato originariamente utilizzato da Stanford per creare uno standard di valutazione per gli LLM in ambito finanziario. Questo studio, condotto ad inizio 2023, aveva come scopo la valutazione della competenza terminologica e della conoscenza domain-specific dei principali modelli generativi disponibili al tempo, principalmente la prima versione rilasciata di GPT-4 e Claude 2.
Noi abbiamo messo a confronto i tre modelli più performanti che il mondo di OpenAI aveva da offrire (GPT-3.5 Turbo, GPT-4 e GPT-4 Turbo) con la famiglia di modelli Claude 3. Il nostro scopo era quello di raccogliere evidenza empirica della superiorità dei secondi rispetto ai primi in ambito finance, rispondendo così alla domanda di quale fosse il migliore modello generalista per questo mercato ad inizio 2024. Dopo aver raccolto le risposte dei modelli, abbiamo proceduto all’analisi delle risposte. Avendo oltre 600 risposte da controllare, abbiamo dovuto creare una pipeline di test e valutazione automatizzata. Ad un LLM (nel nostro caso abbiamo scelto il nuovo GPT-4 Turbo) è stato chiesto di giudicare la correttezza di ogni risposta data. Sebbene fosse un compito relativamente semplice, abbiamo dovuto controllare i risultati a mano e aggiustare varie volte la pipeline di valutazione. Questo è dovuto al fatto ben risaputo in letteratura (fonte: https://arxiv.org/abs/2305.17926) che anche i modelli più raffinati esibiscono dei bias quando gli viene richiesto di giudicare la bontà dell’output di altri modelli (o di loro stessi, come in questo caso).
Di seguito riportiamo i risultati dei test. Nella prima immagine vediamo la percentuale di correttezza per ciascuno dei modelli. Nella seconda, invece, mettiamo in relazione la correttezza con il tempo di risposta.
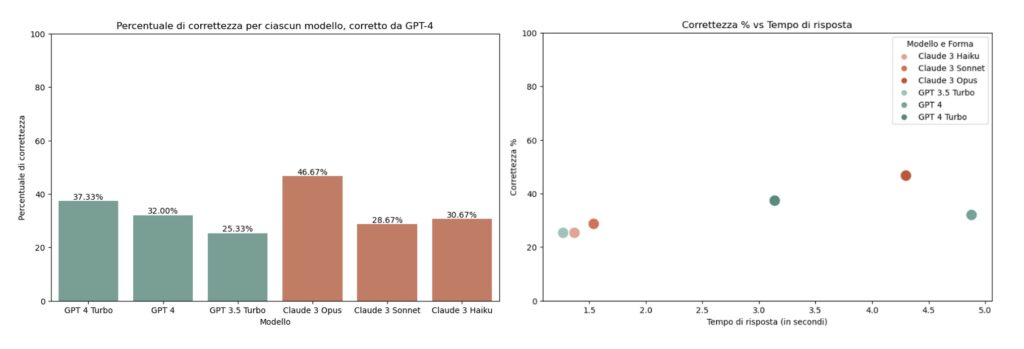
Come si evince dal primo diagramma, Claude 3 Opus ne esce vincitore seguito con un distacco di quasi il 10% dai modelli GPT-4 e GPT-4 Turbo. Controllando, tuttavia, la velocità di risposta dei vari modelli vediamo come una migliore performance correla con una minore velocità di risposta. Questo è dovuto al fatto che i modelli più piccoli sono generalmente più veloci anche se meno precisi. Un’ultima curiosità si può ricercare nel confronto tra il tempo di risposta di GPT-4 Turbo e GPT-4. Il primo, sebbene sia della stessa dimensione del secondo, esibisce un tempo di risposta molto minore.
In conclusione, l'evoluzione dei modelli di intelligenza artificiale, come rappresentato dalla famiglia di modelli Claude 3 di Anthropic, indica una direzione chiara verso la specializzazione e l'ottimizzazione per specifici ambiti di applicazione. L'uso di benchmark specifici, come nel caso del nostro studio nel settore finanziario, è essenziale per valutare le capacità dei modelli in contesti rilevanti. Claude 3 Opus si è dimostrato superiore in termini di precisione rispetto ai modelli concorrenti, anche se con una compensazione in termini di velocità di risposta. Questo dimostra che, oltre alla capacità, anche altri fattori come il costo e la dimensione influenzano le scelte sull'adozione di questi strumenti. L'integrazione dei modelli LLM richiederà un'approfondita valutazione e adattamento per massimizzare i benefici derivanti dall'impiego di questa tecnologia nell'ambito specifico di ogni settore professionale.
LEGGI ANCHE - L’importanza del Prompt Engineering per guidare il comportamento dei modelli di AI generativa
Leggi tutti i nostri articoli