di Damiano Gasparotto e Ivan Masnari, risp.Junior Data Scientist e Software Developer in Excellence Innovation
L’intelligenza artificiale generativa sta facendo passi da gigante, offrendo ogni settimana risultati sempre più sorprendenti. I modelli più recenti e potenti possono elaborare risposte basandosi su un contesto molto ampio, paragonabile addirittura ad un libro di 500 pagine, mentre altri (i “multimodali”), riescono a comprendere diversi tipi di input come immagini, documenti e dataset.
Tuttavia, la maggior parte dei modelli disponibili sul mercato sono “generalisti”: addestrati su un’enorme varietà di dati, ma senza essere specializzati in nessuna attività nel dettaglio. Quando c’è bisogno di avere risposte molto specifiche, l’output non sempre è soddisfacente o consistente, anche utilizzando i modelli più potenti. Inoltre, se si utilizzano modelli “open-weights” o non al top di gamma, la qualità e stabilità delle risposte tende a peggiorare significativamente.
Per approfondire il tema, abbiamo voluto analizzare due aspetti:
– I migliori modelli di mercato sarebbero in grado di superare l’esame OCF di abilitazione alla professione di Consulente Finanziario?
– E’ possibile prendere un modello “open-weights” di dimensioni ben più ridotte, ed addestrarlo per raggiungere lo stesso obiettivo?
L’AI alla prova d’esame OCF
Dopo avere analizzato le performance in ambito finanziario dei principali modelli di intelligenza artificiale, abbiamo proseguito le sperimentazioni con l’obiettivo di valutare l’efficacia di addestrare modelli più piccoli e open- weights, il cosiddetto“fine-tuning”. Come ambito di specializzazione abbiamo selezionato la prova valutativa dell’OCF, l’esame necessario per l’iscrizione all’albo dei Consulenti Finanziari in Italia.
Il test ha previsto 60 domande a risposta multipla sulle cinque materie previste dall’esame ufficiale. Ogni test è stato ripetuto cinque volte per ogni modello, per valutare non solo la correttezza delle risposte, ma anche la loro consistenza.
I modelli che abbiamo sottoposto ai test sono stati:
Modelli di mercato:
- Claude Sonnet 3.5 (ultimo modello di Anthropic)
- GPT-4o (ultimo modello di OpenAI)
- GPT-3.5 turbo (modello OpenAI usato nella versione gratuita di ChatGPT)
Modelli open- weights di piccole dimensioni:
- Llama 3-8B versione base
- Llama 3-8B con nostro fine-tuning
Come si migliora la competenza di un modello
Ci sono due tecniche fondamentali per migliorare la qualità e la precisione delle risposte
- Il prompt engineering: consiste nel formulare le domande o le istruzioni (i “prompt”) in modo da guidare il modello verso risposte più accurate e pertinenti. (abbiamo approfondito questo aspetto in un articolo precedente.
- Il fine-tuning: un processo più avanzato che “riallena” il modello su dati specifici di un settore, trasformandolo da generalista a specialista.
Il fine-tuning è una tecnica di addestramento parziale che permette di ottenere un modello specializzato in un compito specifico. Può essere applicato a tutti i modelli e con diversi livelli di profondità. Una soluzione particolarmente interessante e sempre più adottata riguarda il fine-tuning di piccoli modelli open- weights, che in potenza consente di migliorarne le prestazioni senza richiedere enormi capacità di calcolo.
Come abbiamo addestrato il modello
Per l’esperimento di addestramento abbiamo scelto come modello di base Llama 3-8B, la versione ridotta dell’ultimo modello open- weights di Meta, noto per le sue buone prestazioni in rapporto alle ridotte dimensioni, e abbiamo elaborato un dataset di 5000 domande/risposte, riguardanti le cinque aree principali della prova OCF:
- Diritto del mercato finanziario e degli intermediari
- Diritto previdenziale e assicurativo
- Diritto privato e Diritto commerciale
- Diritto tributario per il mercato finanziario
- Economia e Matematica del mercato finanziario
Il processo di fine-tuning applicato a Llama 3-8B è consistito in un “riaddestramento superficiale”, mirato alla creazione di un nuovo modello che conserva le capacità predittive del modello di base, ma è specializzato nelle cinque aree della prova OCF. Questo tipo di fine-tuning non modifica tutti i parametri, ma coinvolge solo quelli principali (tra l’1% e il 10% del totale).
Risultati dell’esame
Messi alla prova, i modelli di mercato ottengono i risultati migliori, che confermano anche le indicazioni che abbiamo ottenuto nel nostro esperimento precedente: in ambito finanziario, i modelli Anthropic sembrano performare leggermente meglio dei modelli OpenAI.
Ma soprattutto, i risultati del test hanno confermato le potenzialità del fine-tuning. Se il modello Llama 3-8B di base non fornisce risultati soddisfacenti, con il nostro fine-tuning iniziale ha mostrato un miglioramento significativo, con una percentuale di risposte corrette che passa dal 45% al 71%.
Mettendo i modelli a confronto, il modello Llama 3-8B addestrato con nostro fine-tuning ha superato le performance di GPT-3.5 Turbo (61%), e si è avvicinato notevolmente ai risultati dei modelli più potenti sul mercato: GPT-4o (81%) e Claude 3.5 Sonnet (83%).
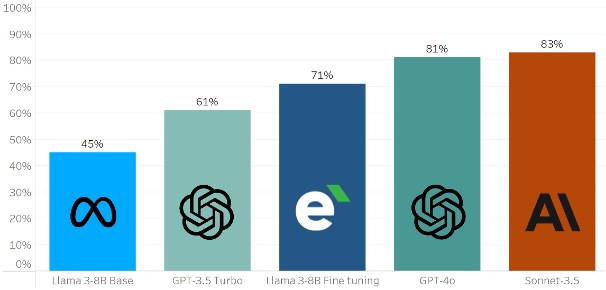
In termini di precisione delle risposte, i risultati sono decisamente incoraggianti per il piccolo modello addestrato. Tuttavia, riteniamo importante sottolineare l’importanza di ulteriori approfondimenti iterativi per migliorare la consistenza delle risposte, che sicuramente farebbero parte di un progetto più corposo.
Il modello base di Meta è coerente (pur dando risposte corrette al 45%) nelle risposte ad ogni domanda in tutti e cinque i round di test. Il nuovo modello addestrato invece ha mostrato una maggiore variabilità, dando la stessa risposta soltanto nel 60% dei casi.
È importante evidenziare che l’instabilità delle risposte del modello addestrato non ha un impatto significativo nei risultati di precisione ottenuti, perché si riscontra principalmente nelle domande a cui il modello non ha saputo rispondere in maniera corretta.
Questo limite di stabilità potrebbe essere affrontato aumentando la dimensione del set di dati per l’addestramento e inserendo ripetizioni di alcune domande nel set. Nel contesto dei large language model (LLM), l’overfitting, generalmente considerato un problema nell’addestramento di nuovi modelli, potrebbe paradossalmente rivelarsi un valido alleato.
Le nostre riflessioni
In conclusione, l’esperimento dimostra l’efficacia del fine-tuning nel migliorare significativamente le prestazioni di un modello più piccolo e open- weights, avvicinandolo alle performance dei modelli più avanzati e proprietari. Questo approccio potrebbe offrire una soluzione interessante per ottenere risultati di qualità in ambiti specifici, mantenendo costi e requisiti computazionali più contenuti.
È sempre importante sottolineare che un ruolo chiave nel fine-tuning è giocato dalla qualità e dalla numerosità dei dati. Con dataset piccoli o di bassa qualità si rischia di ottenere l’instabilità delle risposte senza un miglioramento della correttezza. Pertanto, per sfruttare i vantaggi del fine-tuning, è cruciale concentrarsi nella creazione di dataset ampi, ben strutturati e rappresentativi del dominio specifico in cui si intende specializzare il modello.
